Systematically improving AI Apps through Error Analysis: My Experience
April 22, 2025 by Marius Vach
## Introduction
Building with LLMs is fundamentally different from classic software development.
You can’t predict the output of your system from your input. Because in between the input and output you have an opaque component \- a large language model (LLM). You don’t know how it will react to your input.
That’s why I truly believe that in order to improve your AI apps you have to learn from your mistakes through experiments. You have to look at your inputs and outputs, see where your system goes astray and think about ways to fix it.
In this blog post I want to show you how I systematically improved a LLM-based app using error analysis.
Most of my experience comes from working on a LLM-based chatbot for medical guidelines (the paper is out soon hopefully) and my work on https://wilhelmai.mariusvach.com \- a LLM app that gives you answers to radiology-related questions grounded on authoritative and trustworthy sources.
Also the works by [Hamel Husein](https://hamel.dev) and [Jason Liu](https://jxnl.co/) have been a huge inspiration for this whole approach.
### Wilhelm.ai
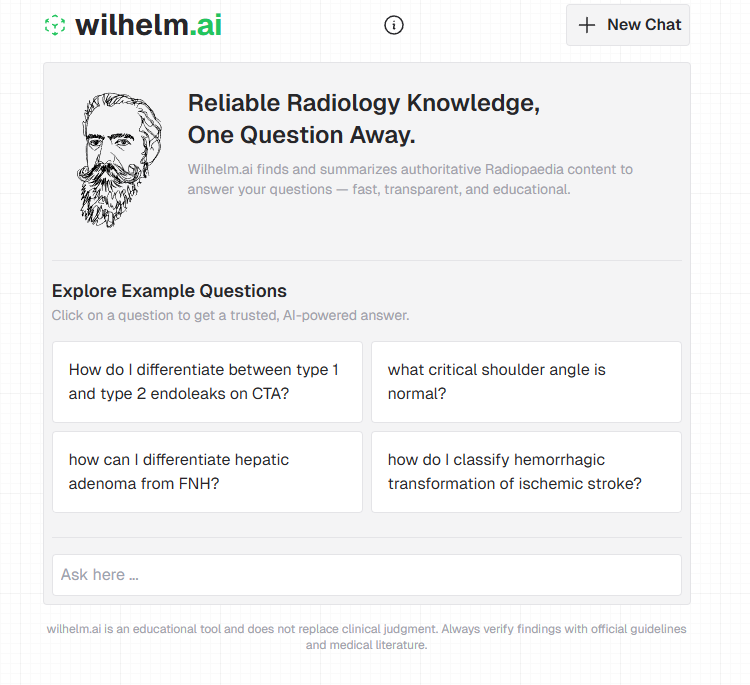
In order to understand the post better, it’s beneficial if I show you how wilhelm.ai works and what it does. I refer to it for examples often. This is a schema of the app: 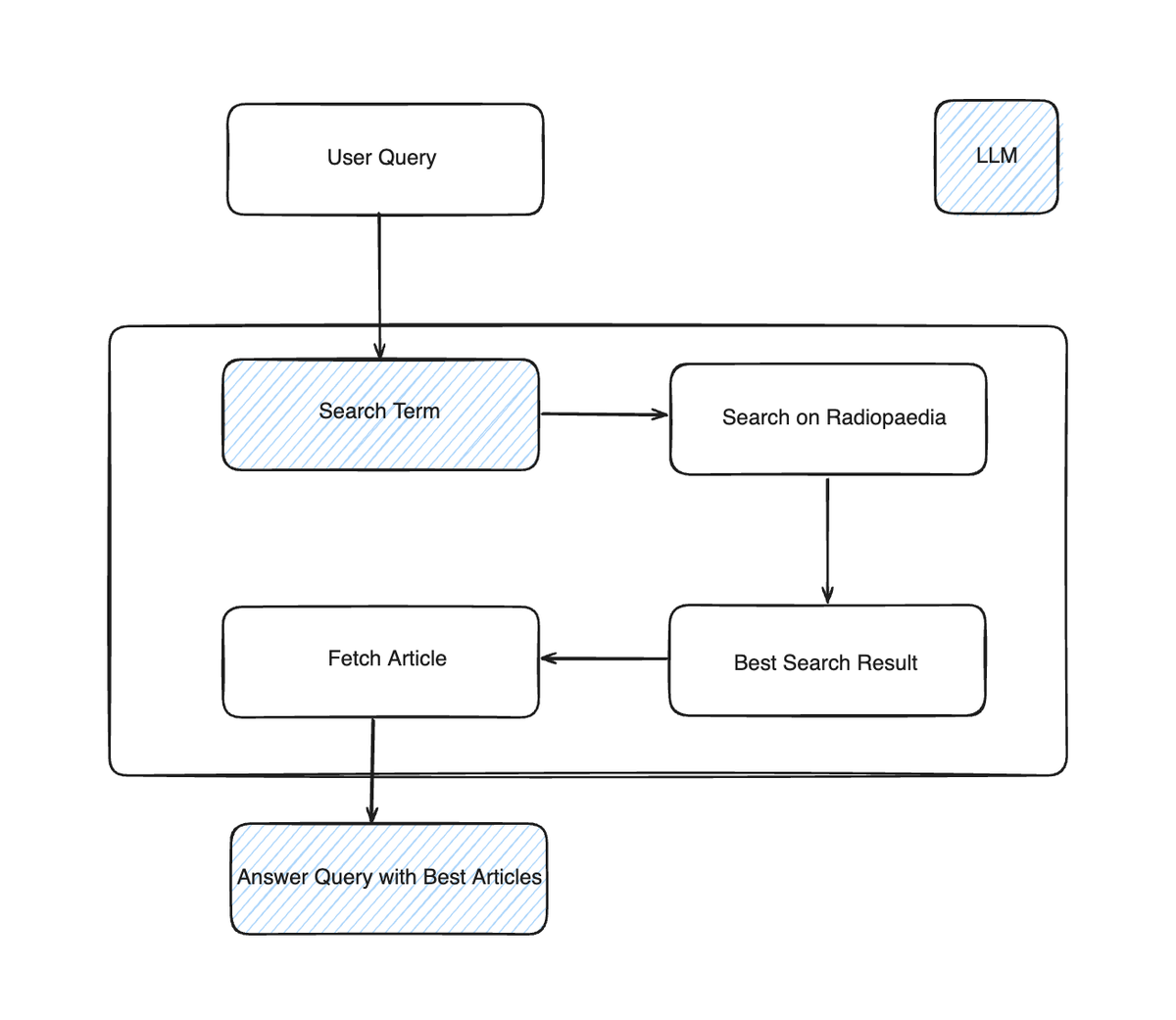
Wilhelm.ai answers the user query, by using content from radiopaedia.org (Radiopaedia is a huge open radiology encyclopaedia).
What the system does is the following:
1. A LLM translates the user query in one or more search term
2. The system searches for the search term on radiopaedia.org
3. The best search results get picked
4. The content of the best search results is provided to the LLM as context for answering the user query
So it’s basically a retrieval-augmented generation (RAG) app, but with the twist of using the search functionality of a website as it’s retrieval mechanism.
But now let’s get into the actual process of error analysis.
## Process
When I say “systematically improve” I mean implementing a cyclical process for evaluating and improving your LLM system that looks like this:
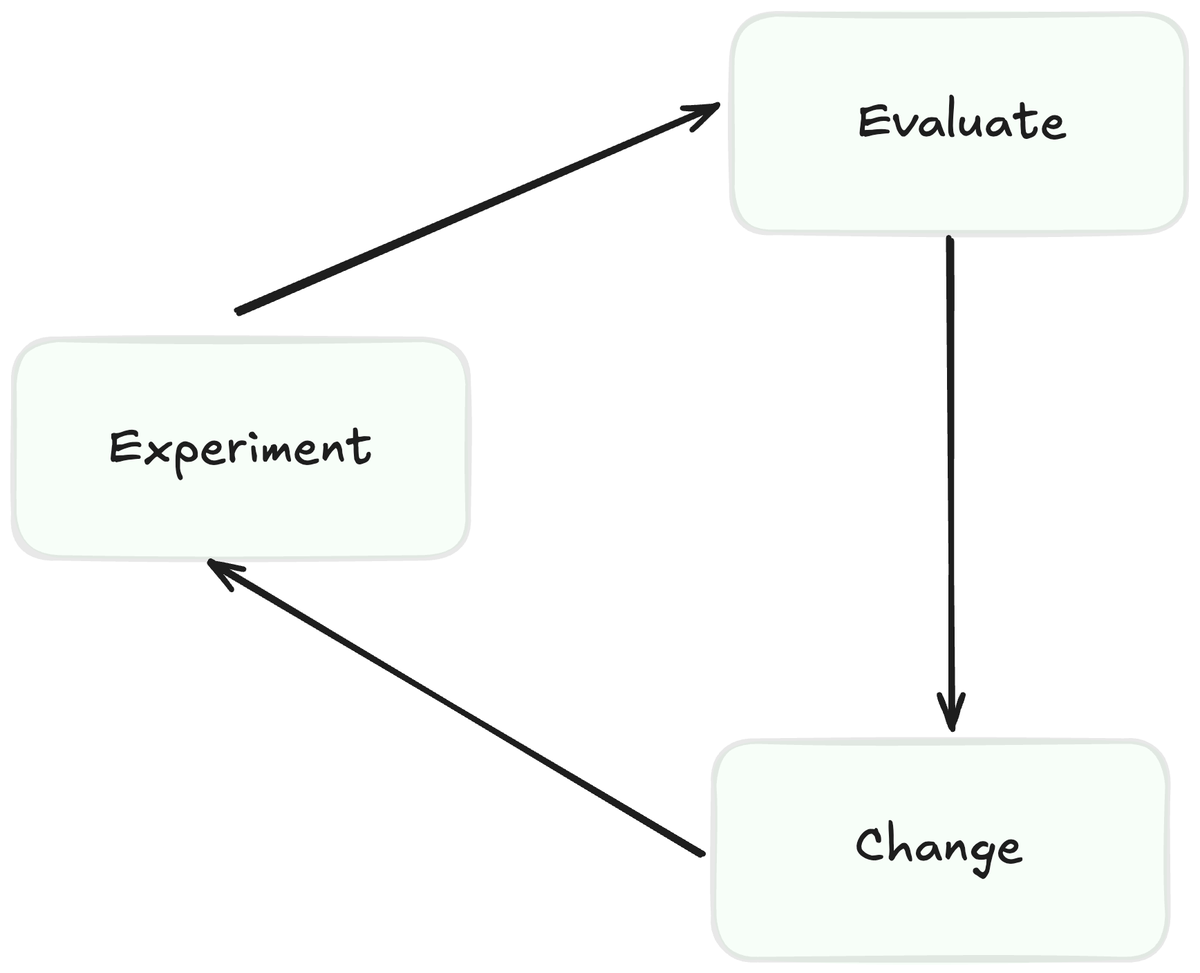
1. We **evaluate** the errors of our system
2. We make a hypothesis on how to improve our outputs. We apply those **changes**.
3. We test the hypothesis by running an **experiment**
4. ….aaaaand we start at 1\) again.
This looks an awful lot like the [“scientific method”](https://en.wikipedia.org/wiki/Scientific_method). As science is grounded in empirical observations so is improving LLM systems.
You cannot trust anything. You have to test everything.
In my experience, the real magic lies in looking at the output and analysing why errors occur. This unlocks very obvious ways to improve your LLM system. And that’s the focus of this post.
As a side note:
In the beginning the most important thing is to get started with the process. It doesn’t have to be perfect.
Your experiments don’t have to be perfect.
Your evaluation technique doesn’t have to be perfect.
Just start.
In the beginning the problems of your app will be so obvious that you don’t need fine-grained instruments to detect them. Later, when the problems become more subtle, it’s more important to have nailed all of the components of the process to have the instruments to detect the little signal that’s somewhere in the noise.
You can refine the process later. Don’t just iterate on your app, but also on the way you evaluate it.
Okay now let’s go through the process together (with examples from Wilhelm.ai).
## Get Your Test Queries
First, we need some data to run our experiments with. We need some test inputs.
Here you have two options (that are not mutually exclusive):
1. You can either use **real world user queries**.
2. Or you can generate **synthetic queries**.
If you have real user queries, you can just pick a subset of them and use it as your test query set.
If you don’t have real user queries or maybe not enough, you can just prompt a LLM to generate test queries for you.
The prompt doesn’t have to be complicated. I found that few-shot prompting works best for generating example queries. Paste some existing queries into your favorite LLM and let it generate 50 more queries similar to the ones you pasted in.
I think of test queries like unit test cases. I have different test queries to test different things in my AI app.
With Wilhelm.ai I struggled a lot with comparison-style queries like “How to differentiate x from y?”. So I wrote a bunch of example queries in this style myself and let ChatGPT generate more in the same style.
Another thing:
ChatGPT-generated queries tend to be very clean. They don’t contain typos or bad punctuation. To simulate real user queries, I pasted a bunch of queries into ChatGPT and prompted it to “rough them up” (“What are the imaging findings of primary CNS lymphoma vs. glioblastoma?” \=\> “cns lymphoma vs gbm”). This way I tested that my app can’t just handle perfectly written queries but that it’s somewhat robust against different query forms.
## Experiment
This part is actually very simple.
You take your test queries and run them through your system, while saving the outputs and any additional information you need to evaluate your system (the trace).
In my concrete case that meant I took my .txt file of test queries and ran them through the main function of my app. I not only saved the user input and the final answer but also the search terms the LLM generated from the user query as well as the Radiopaedia articles that were picked as the most fitting result.
Again, don’t complicate it here. In the beginning you don’t need complex tooling or anything. I have my test queries in a .txt file with one query per row. I save the results of my experiments to a .json file. This system doesn’t scale well, but in the beginning [do things that don’t scale](https://www.paulgraham.com/ds.html). Improve later.
## Evaluate
Here comes the fun part.
You have your results from your experiment. Now it’s time to look at the data, analyze the errors and make a plan on how to eliminate those errors.
But, how do I look at my data? Glad you asked.
While a spreadsheet might suffice here, I advise you to build a custom data viewer that’s tailor-made to your specific use case. Every data looks different and every app has different intermediate data that leads to the output.
It’s important to lower the barrier to looking at your data as much as possible. Otherwise you won’t do it often enough. You want to have every information you need to evaluate your app in one screen.
For Wilhelm.ai I need not only to look at the user query and the output but I also need to see the search term the LLM generated as well as the results coming back from the search on radiopaedia.org and what articles were picked.
I built a very simple web app for my use case using FastHTML ([https://fastht.ml](https://fastht.ml)). It’s what I know best and with which I’m fastest. But please use whatever you want. There are a lot of great Python options nowadays for building these kinds of internal tools, like [Streamlit](https://streamlit.io/), [Gradio](https://www.gradio.app/) or [Shiny for Python](https://www.gradio.app/).
Below you see a screenshot of my data explorer app. It has 130 lines of code (including markup and imports). [Here is a gist](https://gist.github.com/vacmar01/db3164a15a184955a7a50486706ed58e) with the complete code.
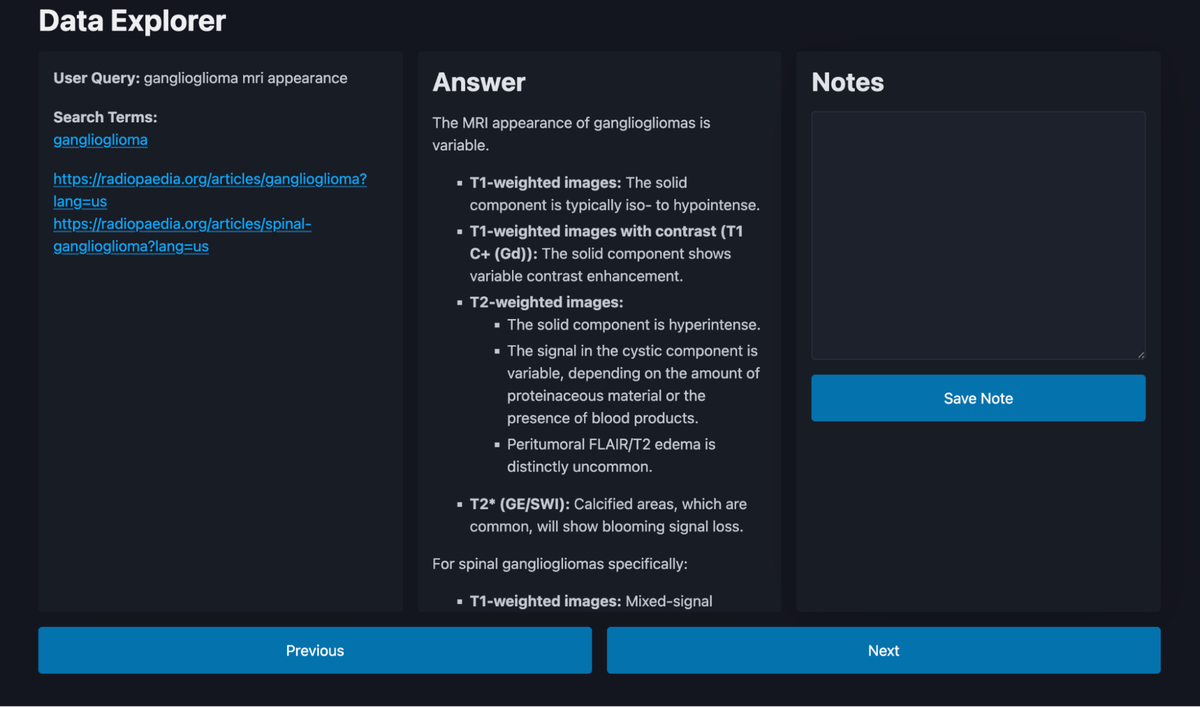
Here is what you should display in this app:
* user input
* app output
* free form notes
* \+ any relevant intermediate information that leads to the app output
It’s just for your personal internal use. It doesn’t have to be pretty or generalizable. It just has to be more effective than working with Excel (and that’s not a high barrier).
The main thing is that you have a way of capturing free form comments on your data (I tend to comment only on things I consider “errors”). It’s important that the *evaluations are free form*. A checklist or predefined form won’t cut it here.
**In the beginning you don’t know what your dimensions for evaluating your results are. That’s the task of error analysis.**
An error is every answer that doesn’t satisfy the user query \- and that may be subjective. That’s why it’s so important that you work with domain experts on this. You need people that are potential users of your app. And these people have to judge your output. That’s the key point of working with LLMs. Whether the output is correct or not cannot be reasoned about theoretically or formally and the definition of correct is much more vague than with normal computer programs.
Here are some example notes I took in one iteration on Wilhelm.ai:
*“The best search result would be in position 2 here. The retrieved article about powassan virus doesn't answer the user query.”*
*“The LLM doesn't use the context for answering the query. This is a big nono. It should have said "I don't know", since the retrieved article is bad (the LLM realized it on its own). Position 2 would be better.”*
*“The search term is too specific and thus the correct result is at position 5 and not position 1\. If it would have used "patellar height" and not "patellar height measurement" as the search term, the correct article would be on the top.”*
I save all notes in a SQLite database ([https://github.com/AnswerDotAI/fastlite](https://github.com/AnswerDotAI/fastlite) makes this very convenient).
Once you've gone through your test set and annotated the errors, the challenge is to synthesize these individual observations into actionable patterns. This is where analyzing your collected notes comes in...
### Analyzing your notes
When I’m done going through my test queries and answers one by one and commenting on the errors I see, I export all of my notes and feed it into a LLM (wrote about that before: [https://blog.mariusvach.com/posts/i-love-r1](https://blog.mariusvach.com/posts/i-love-r1)). I then task the LLM to identify common patterns.
Of course, it’s still your job as the developer to assess the LLM output critically. It may miss nuances or misinterpret the meaning of some notes.
My favorite LLMs for this task are either **Deepseek R1** or **Gemini 2.5 Pro,** but you have to experiment a little for yourself here.
Here is the exact prompt I used for my last run on this in Gemini 2.5 Pro:
*“\*
*Cluster these notes about LLM responses of a RAG system into different groups and give an overview of what group occurs how often (in percent) and what I should improve first based on these notes.*
*The goal of the RAG system is to give educational, trustworthy answers for radiological queries based on radiopaedia content.”*
With DeepSeek R1 I had very good results with a prompt like this:
*“Find patterns in this array of comments for RAG results and give me a concise summary of the patterns detected:*
*\”*
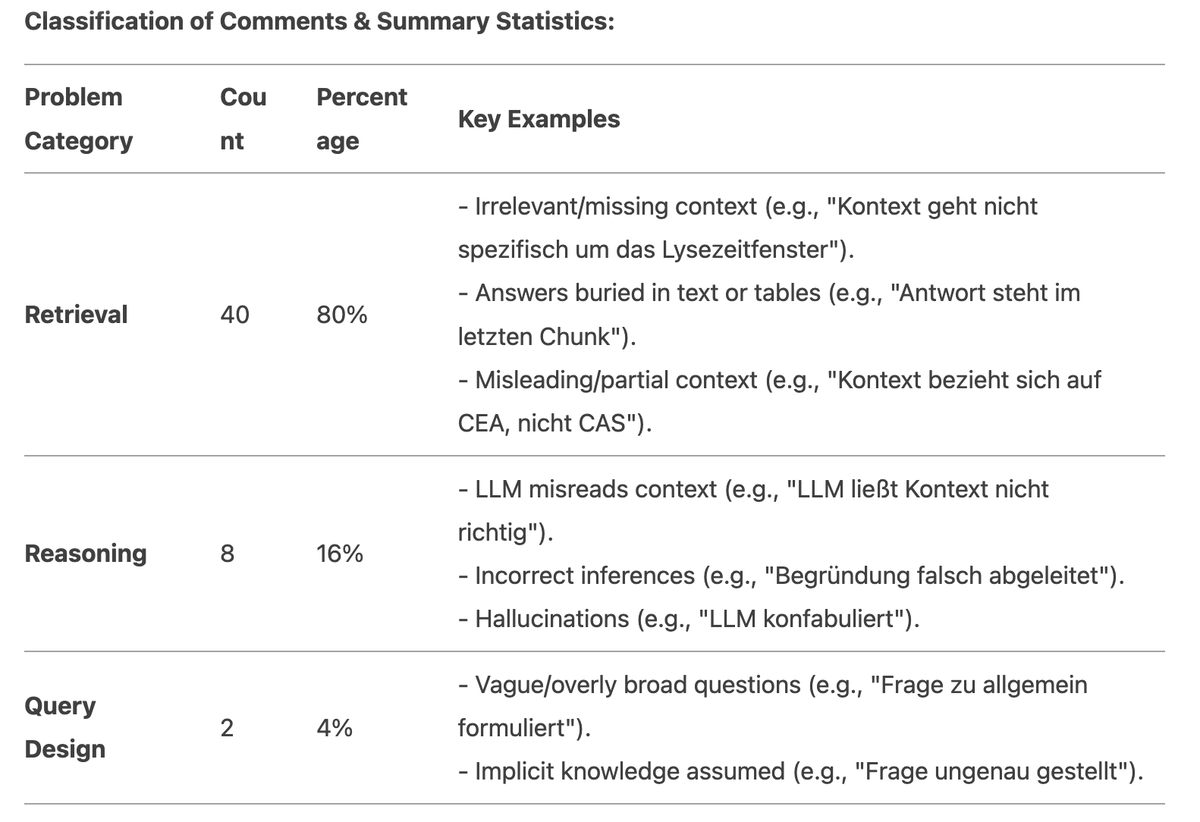
After prompting it again, R1 generated this nicely looking table with an overview of the different problem categories, their relative occurrence and key examples.
## Change
The previous step gave you a clear indication on what to work on next.
Maybe you need to work on your retrieval or maybe there is a change you can do to the system prompt. But the logical next step should be clear.
After making this change you have to run the same process again. Depending on the errors you identified it may be a good idea to expand your test set with specific queries to test certain parts of your system.
Nonetheless, I advise using a broad test query set. You’ll want to make sure that your changes didn’t cause a regression for other types of queries or at a different part of the system.
Especially because LLM systems are so opaque and complex, you can’t know in advance how your change will actually affect the system. You have to test it. This is the whole idea.
## My Experience
Let me share my personal experience with error analysis.
I came across error analysis first on a research project on question answering over medical guidelines.I thought it would be scientifically interesting to see what part of the whole system was responsible for the errors we were seeing while evaluating the results.
It just felt natural to me: Look at the errors, take notes and then make sense of these notes. That’s a common workflow in science.
It became clear quite fast that the retrieval step was the main error source. This motivated us to evaluate different retrieval models and added the analysis to the paper as well. Actually BM25 outperformed every embedding model we tried on a synthetic retrieval test set.
Before I started working on Wilhelm.ai, I read several posts by Hamel and Jason on how to systematically improve LLM systems and I was amazed by how similar their approach was to what I did for my research paper. B
But I was also amazed by how clear of a path forward it gave to me. After every iteration of taking notes on my errors, it became crystal clear on what to work on next.
To give you an example of the things I encountered:
In one of the first versions of the app, I used a LLM as a reranker:
- I structured the search results as JSON
- Then I prompted a LLM to pick the best search result for the given query.
This kind of worked. But was a little bit “wonky” and it added a lot to the latency of the whole system.
To lower the latency I tried out a “normal” reranker model by Jina.ai.
Then I started doing the first real iteration of the system above and I saw that the “best” search result picked by the reranker was crap. These are my notes from this iteration:

You don’t have to be a genius to see that using a simple heuristic of just picking the first search result instead of having a complicated reranking step would perform much better. The newest version right now actually picks the first two search results, as a simple hack to mitigate problems where Radiopaedia search has the best search result on position \#2. Works like a charm.
This highlights a key principle: components that theoretically *should* improve performance must still be validated empirically within *your specific system and data*. Don't assume off-the-shelf components will work optimally without testing.
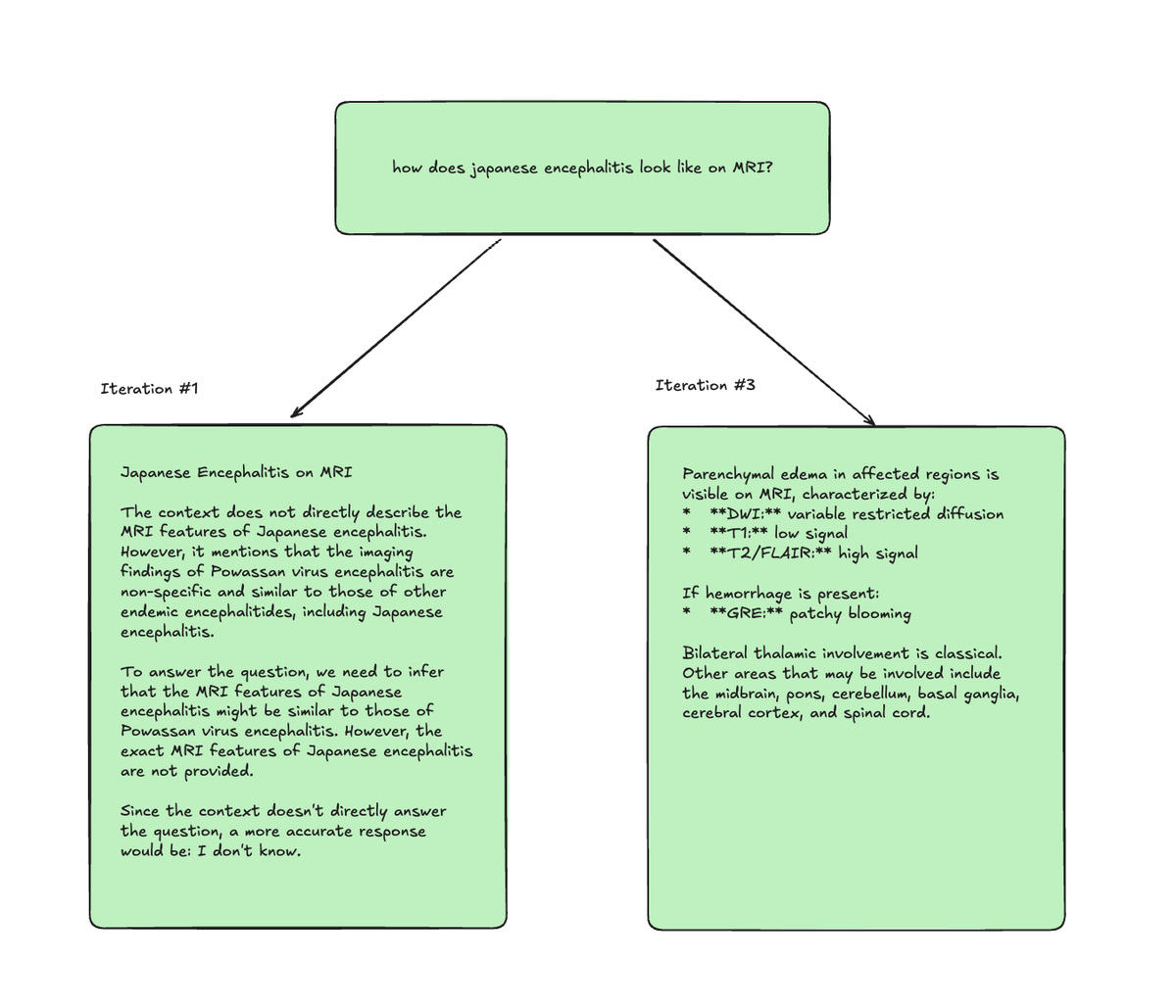
An example of how iterating on my app through error analysis helped me improve my output, look at the following image. This was just 3 iterations. Something you can do in maybe 2 hours \- depending on the size of your test query set. Think about how much you can improve your product when really nailing down this process and doing 100s of iterations.
## Conclusion
The approach I outlined here should get you started on your way of systematically improving your LLM system by analyzing the errors it produces. It should give you clear areas for improving your product.
I held it scrappy on purpose. I’m a true believer in “start first, perfect it later”. You can improve your data explorer app over time, maybe adding a way for non-technical domain experts to work with you on evaluating the output or implementing a more sophisticated way of tracking experiments.
Of course you can also scale up the evaluation process with techniques like LLM-as-a-judge but I would always advise having a human in the loop. They don't have to go through the whole test set every time, but having a human looking at your data regularly is mandatory.
The most important thing is to get started.
## Wanna talk?
Want to talk about systematically improving your LLM apps? Write me a message on [Twitter ... eh X](https://twitter.com/rasmus1610), [LinkedIn](https://www.linkedin.com/in/dr-marius-vach-32a447201/) or write me a mail (mariusvach at gmail com).
## Further reading
[A Field Guide to Rapidly Improving AI Products – Hamel’s Blog](https://hamel.dev/blog/posts/field-guide/)
[What We’ve Learned From A Year of Building with LLMs – Applied LLMs](https://applied-llms.org/)
[Your AI Product Needs Evals – Hamel's Blog](https://hamel.dev/blog/posts/evals/)
[The RAG Playbook \- Jason Liu](https://jxnl.co/writing/2024/08/19/rag-flywheel/)
[Systematically Improving Your RAG \- Jason Liu](https://jxnl.co/writing/2024/05/22/systematically-improving-your-rag/)