A very common pattern in web apps in calling an LLM through an API.
And as we all know, LLMs are slow - at least compared to everything else we do in a web app.
Just waiting for them to finish in a normal GET or POST request is usually not a good idea. HTTP requests time out after 60 seconds by default and the web app is unresponsive while the request is running. That's not a good user experience.
So, somehow we need to handle these long-running tasks in our `FastHTML` app.
Hamel Hussein already wrote a [nice blog post](https://hamel.dev/notes/fasthtml/concurrency.html) about this, but I wanted to explore one of the approaches a little more.
Welcome to the beautiful (and frightening) world of `asyncio`.
If you have spend any time in JavaScript land, then you are familiar with `async`/`await` and asynchronous programming in general. It's the only way you can write "concurrent" code in JavaScript since the language itself only uses one thread.
If you need an refresher or you want to understand the idea behind asynchronous programming vs. parallel programmin, the FastAPI docs have [a great post](https://fastapi.tiangolo.com/async/).
It uses an event loop to handle concurrency and that's what `asyncio` implements for Python as well.
Don't know what an event loop is and how to think about it? No worries, I hadn't had a clue as well. But [this awesome talk](https://www.youtube.com/watch?v=8aGhZQkoFbQ) enlightened me.
And Claude assured me that the overall mental model is the same for `asyncio` in Python. The only difference is that Python has the luxury that it can use the underlying event loop of the operating system for scheduling purposes and it doesn't have to invent it's own implementation like JavaScript in the browser has to do.
Anyway, I'm disgressing.
The beauty is that `FastHTML` is built on `Starlette` which in turn implements the `ASGI` protocol, which is basically the asynchronous predecessor of `WSGI`, the "old" Python web server protocol.
What that means is that your `FastHTML` webapp runs in an event loop anyway. That makes writing asynchronous code in FastHTML quite natural.
And asynchronous code is perfect for networking and our use case.
So let's see how we can utilize this knowledge to implement a very simple task system in FastHTML that handles long running stuff, like API calls.
We will use the Anthropic API as an example and build a very basic web interface for talking to a LLM.
So let's dive into the code.
Create a new python file and enter the following code. If you are in a fresh environment you have to install `python-fasthtml` and `claudette` as well as `python-dotenv` if you want to read in your Anthropic API Key from a `.env` file.
```python
from fasthtml.common import *
import asyncio
from claudette import *
from dotenv import load_dotenv
load_dotenv()
c = AsyncClient(model=models[2]) # model[2] should be Claude Haiku
app, rt = fast_app()
# more code goes here
serve()
```
Here we just import everything, instantiate a new **async** client of `claudette` to talk to an Anthropic model.
Then we instantiate a new FastHTML app.
```python
tasks = {}
```
We will use a simple in-memory dictionary for keep track of our tasks. Yes, it will be destroyed when we restart the server, but since "long-running" means a running time of maybe 60 seconds maximum for a LLM call, I think that's okay.
And yes, scaling the app over multiple servers also won't work with this setup. But when your app gets that big that one beefy server isn't enough anymore, first congratulations, and second, you should have the resources to implement something similar with Redis easily.
```python
async def get_llm_response(query: str):
r = await c(query)
return r.content[0].text
```
Next we'll define the actual long running task, in our case, the LLM query. We'll define it as a `coroutine` in Python (marked by the `async` keyword).
Now let's define our index route handler:
```python
@rt
def index():
return Titled(
'Long running',
Form(hx_post=generate.to(), hx_target="#result", **{"hx-on::after-request":"this.reset()"})( # this is a neat trick to reset the form after submission
Input(type="text", name="query"),
Button("Submit", type="submit"),
),
Div(id="result")
)
```
This just defines a simple Form element with an text input and a button. Underneath we have a div that will receive our result.
As you can see, the form posts to `generate`, so let's implement this endpoint next.
```python
@rt
async def generate(query: str):
if not query:
return Div("No query provided")
task = asyncio.create_task(get_llm_response(query=query))
task_id = id(task)
tasks[task_id] = task
return Div("Processing...", hx_get=check.to(task_id=task_id), hx_trigger="every 1s", hx_swap="outerHTML")
```
This endpoint receives the query through the form submission. If it is empty, we'll return a rudimentary error message.
If we have a query, we'll create `asyncio` `Task` using the `get_llm_response` coroutine we defined earlier. This will run the `coroutine` concurrently. A `Task` is very similar to a `Promise` in JavaScript land.
`asyncio.create_task()` returns the task object created. The `id()` function of the Python standard library returns the memory address of any object as an integer. We use it the key to save the task to our task dictionary.
Then we'll return a `Div` that polls the `check` endpoint every second. HTTP polling is a very simple but sufficient technique for dealing with events. It does nothing else than sending a get request to the `check` endpoint one second after it has been loaded. Since the endpoint returns the same HTML element again if the task hasn't finished it will perpetually call this endpoint every second until the task has finished.
To see what the `check` endpoint does, let's implement it next:
```python
@rt
async def check(task_id: int):
task = tasks[task_id]
if task.done():
result = task.result()
del tasks[task_id]
return Div(H2("Result"), result)
return Div("Processing...", hx_get=check.to(task_id=task_id), hx_trigger="every 1s", hx_swap="outerHTML")
```
The endpoint retrieves the task through it's `task_id` from our `tasks` dict. Every asyncio `Task` has a `done()` method that returns `True` if the coroutine finished running. If the task has finished, we'll retrieve the result of the coroutine using the `result()` method, delete the task from our dictionary and return a `Div` with the result.
If it hasn't finished, we'll return the same `Div` as before so that our web app keeps on polling the `check` endpoint until the task is finished.
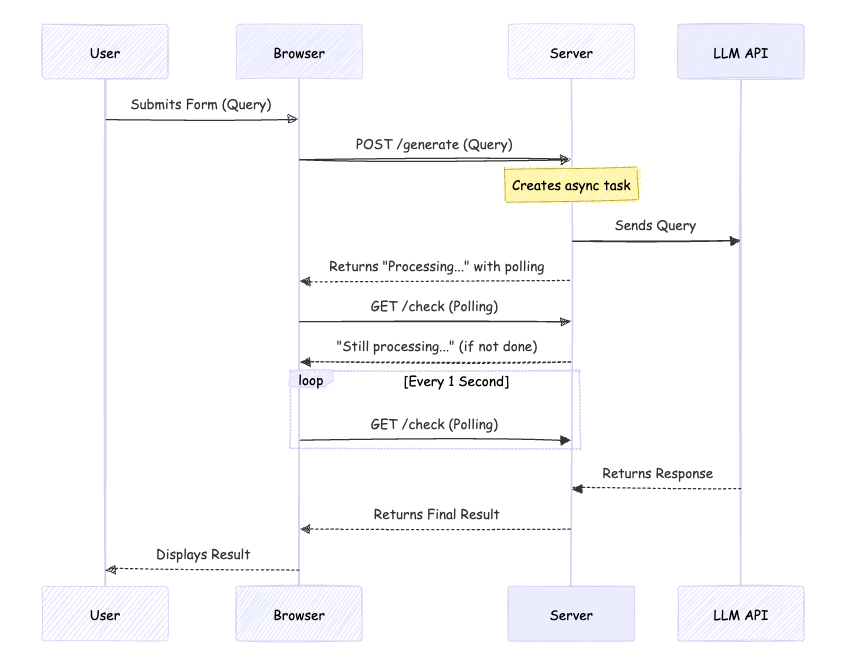
So as you can see, it's not that difficult to deal with long running tasks in FastHTML/ASGI. The beauty is that ASGI is async by default, which makes dealing with this kind of stuff very easy. With WSGI apps like Flask or Django, this because a little bit more awkward.
As it turns out, there is an even more elegant approach for dealing with LLM queries in FastHTML/HTMX that also enables streaming of the response, further improving the UX of your app. The technique is called "server-sent events (SSE)" and is part of the HTTP spec.
But this will be a topic for a future post.